Двухвыборочный z-тест для средних в EXCEL
11 декабря 2016 г.
- Группы статей
- Статистический вывод
Рассмотрим использование MS EXCEL при проверке статистических гипотез о разнице средних значений 2-х распределений в случае известных дисперсий. Вычислим значение тестовой статистики Z 0 , рассмотрим процедуру «двухвыборочный z-тест», вычислим Р-значение (Р- value ). С помощью надстройки Пакет анализа сделаем «двухвыборочный z-тест».
Имеется две независимых случайных величины. Эти случайные величины имеют распределения с неизвестными средними значениями μ 1 и μ 2 . Дисперсии этих распределений известны и равны σ 1 2 и σ 2 2 соответственно (в общем случае дисперсии могут быть не равны). Из этих распределений получены две выборки размером n 1 и n 2 .
Необходимо произвести проверку гипотезы о разнице средних значений этих распределений: μ 1 - μ 2 (англ. Hypothesis Tests for a Difference in Means, Variances Known).
Нулевая гипотеза H 0 звучит так: разница средних значений равна Δ 0 , т.е. Δ 0 = (μ 1 - μ 2 ). Часто предполагается, что Δ 0 =0, следовательно, μ 1 = μ 2 (значение Δ 0 задается исследователем исходя из условий решаемой задачи).
Альтернативная гипотеза H 1 : (μ 1 - μ 2 )<>Δ 0 . Т.е. нам требуется проверить двухстороннюю гипотезу . Для этого делается по одной выборке из каждого распределения.
Примечание : Про построение соответствующего двухстороннего доверительного интервала можно прочитать в этой статье Доверительный интервал для разницы средних значений 2-х распределений (дисперсии известны) в MS EXCEL .
СОВЕТ : Для проверки гипотез нам потребуется знание следующих понятий:
- дисперсия и стандартное отклонение ,
- выборочное распределение статистики ,
- уровень доверия/ уровень значимости ,
- стандартное нормальное распределение и его квантили .
Сначала дадим точечную оценку для Δ 0 .
Точечной оценкой для μ 1 - μ 2 является разница между средними значениями, вычисленными на основании выборок из этих (независимых) распределений, т.е. Хср 1 - Хср 2 . Это следует из свойства математического ожидания : Е(Хср 1 - Хср 2 )= Е(Хср 1 )-Е(Хср 2 )= μ 1 - μ 2
Хср 1 - Хср 2 является случайной величиной, и как любая другая случайная величина, она имеет свое распределение вероятности. В данном случае, эта случайная величина распределена по нормальному закону . Это следует из того, что Хср 1 и Хср 2 распределены по нормальному закону (см. статью про ЦПТ ), а их линейная комбинация Хср 1 - Хср 2 также имеет нормальное распределение (см. статью про нормальное распределение ).
Теперь вычислим дисперсию этого распределения. На основании свойств дисперсии имеем, что VAR(Хср 1 - Хср 2 )= VAR(Хср 1 )+ VAR(Хср 2 ) = σ 1 2 /n 1 + σ 2 2 /n 2 . Следовательно, стандартное отклонение точечной оценки равно
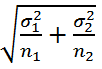
Если вычисленное на основе выборок значение Хср 1 - Хср 2 будет «существенно отличаться» от Δ 0 ( нулевая гипотеза ), то это будет являться основанием для принятия альтернативной гипотезы .
Выражение «существенно отличаться» означает, что Хср 1 - Хср 2 , не попадет в определенную область значений. Эту область значений называют доверительным интервалом .
Часто ширину
доверительного интервала
определяют в
стандартных отклонениях
случайной величины, которая является
точечной оценкой
искомого параметра (в нашем случае
стандартное отклонение
величины Хср
1
- Хср
2
равно
.
Т.к. величина Хср
1
- Хср
2
имеет
нормальное распределение
, то с вероятностью 95% значение этой величины, вычисленное на основании
выборок
, попадет в интервал ограниченный +/-2
стандартных отклонений
относительно Δ
0
.
Если это не произошло, то это является основанием для отклонения
нулевой гипотезы
, т.к. такое событие считается маловероятным (если справедлива
нулевая гипотеза
)
.
Для иллюстрации вышесказанного, в файле примера на листе Сигма известна построена диаграмма с доверительным интервалом (для случая двухсторонней гипотезы ).
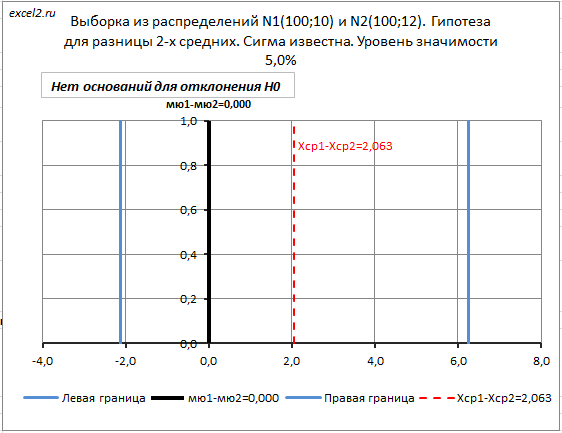
Здесь доверительный интервал построен не относительно значения Δ 0 , а относительно величины Хср 1 - Хср 2 , вычисленной на основании выборок . Если Δ 0 попадает в доверительный интервал , то у нас нет основания отвергать нулевую гипотезу . Если Δ 0 окажется за пределами доверительного интервала, то будет принята альтернативная гипотеза .

Значения выборок в файле примера генерируются с помощью формулы =НОРМ.ОБР(СЛЧИС();B38;B7) . Поэтому, при нажатии клавиши F9 или при изменении данных на листе, значения выборок генерируются заново. Это приводит изменению значения Хср 1 - Хср 2 и, соответственно, к изменению границ интервала.
Примечание : Доверительный интервал можно построить и относительно Δ 0 . В этом случае его границы не будут изменяться при обновлении значений выборок . Но, величина Хср 1 - Хср 2 будет по-прежнему изменяться. Если Хср 1 - Хср 2 окажется за пределами доверительного интервала, то будет принята альтернативная гипотеза .
СОВЕТ : Перед проверкой гипотез о равенстве средних значений полезно построить двумерную гистограмму , чтобы визуально определить центральную тенденцию и разброс данных в обеих выборок .
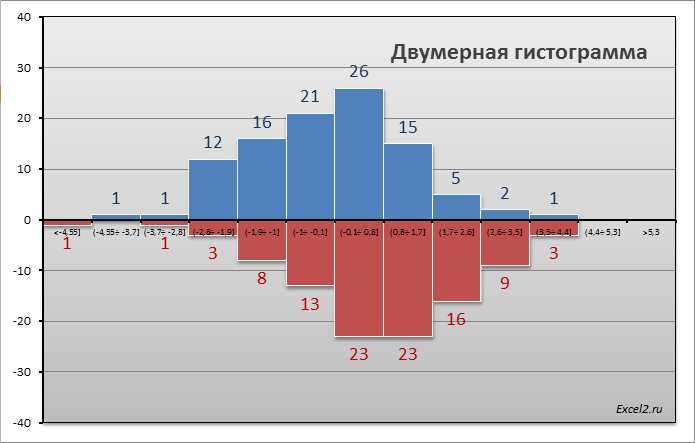
Примечание : Вышеуказанные распределения не обязательно являются нормальными . Однако, требуется чтобы выполнялись условия применимости Центральной предельной теоремы .
Теперь рассмотрим проверку гипотез с помощью процедуры z -тест .
Двухвыборочный z-тест для средних
Процедура проверки гипотезы о разности средних значений 2-х распределений в случае известных дисперсий имеет специальное название: двухвыборочный z-тест для средних (z-Test: hypothesis tests for a difference in means, variances known).
По аналогии с одновыборочным z-тестом , тестовой статистикой для проверки гипотез данного вида является случайная величина Z:
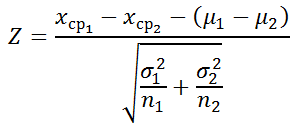
где Хср 1 и Хср 2 – средние выборок , а n 1 и n 2 – размеры этих выборок .
Данная тестовая статистика , как и любая другая случайная величина, имеет свое распределение. В процедуре проверки гипотез это распределение называют « эталонным распределением », англ. Reference distribution. В нашем случае Z -статистика имеет стандартное нормальное распределение .
Установим требуемый уровень значимости α (альфа) = 0,05 (допустимую для данной задачи ошибку первого рода , т.е. вероятность отклонить нулевую гипотезу , когда она верна).
Напомним, что значение, которое приняла z -статистика обозначим Z 0 .
Если вычисленное на основе выборок значение Z 0 , в случае двухсторонней гипотезы , будет в области значений ограниченной нижним и верхним α/2-квантилями стандартного нормального распределения, то у нас не будет основания отвергнуть нулевую гипотезу. Это утверждение эквивалентно рассмотренному выше случаю, когда Хср 1 - Хср 2 окажется в пределах соответствующего доверительного интервала (действительно, согласно вышеуказанной формуле, Z 0 является стандартизированным значением Хср 1 - Хср 2 ) .
Примечание : Верхний α/2-квантиль - этотакое значение случайной величины z , что P ( z >= Z α /2 )=α/2. Верхний α/2-квантиль стандартного нормального распределения обычно обозначают Z α/2 . Подробнее о квантилях распределений см. статью Квантили распределений MS EXCEL .
В нашем случае, необходимо будет вычислить только верхний α/2-квантиль, т.к. он равен соответствующему нижнему квантилю со знаком минус. Следовательно, условие отклонения нулевой гипотезы можно записать как |Z 0 |>Z α/2 .
Чтобы в MS EXCEL вычислить значение Z α/2 для различных уровней значимости (10%; 5%; 1%) - используйте формулу =НОРМ.СТ.ОБР(1-α/2) .
Итак, если формула =ABS(Z 0 ) вернет значение больше, чем результат формулы =НОРМ.СТ.ОБР(1-α/2) , то это означает, что необходимо отвергнуть нулевую гипотезу (вычисления приведены файле примера на листе Сигма известна ) .
Для односторонней альтернативной гипотезы (μ 1 - μ 2 )>Δ 0 , нулевая гипотеза будет отвергнута в случае Z 0 >Z α .
Для односторонней альтернативной гипотезы (μ 1 - μ 2 )<Δ 0 , нулевая гипотеза будет отвергнута в случае Z 0 <-Z α .
Вычисление Р-значения
При проверке гипотез, помимо z -теста, большое распространение получил еще один эквивалентный подход, основанный на вычислении p -значения (p-value). Поясним его на основе двухсторонней гипотезы H 0 : μ 1 - μ 2 = Δ 0 .
Напомним, что если двухсторонняя гипотеза H 0 утверждает, что μ 1 - μ 2 =Δ 0 , то она отвергается в случае если |Z 0 |>Z α/2 . Выражение |Z 0 |>Z α/2 эквивалентно Z 0 >Z α/2 (для положительных Z 0 ) и Z 0 <-Z α/2 (для отрицательных Z 0 ), т.к. величина Z α/2 всегда положительная.
Вышеуказанные значения z -статистики имеют размерность анализируемой случайной величины, но их трудно интерпретировать. Чтобы облегчить понимание критерия отклонения нулевой гипотезы преобразуем неравенство |Z 0 |>Z α/2 .
Вспомним
график плотности функции распределения
из
статьи про квантили стандартного нормального распределения
.
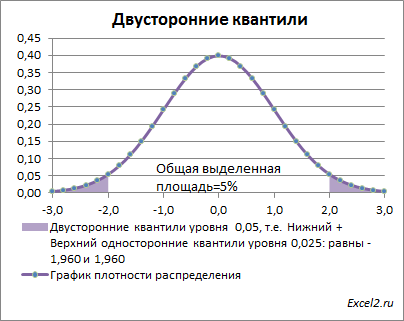
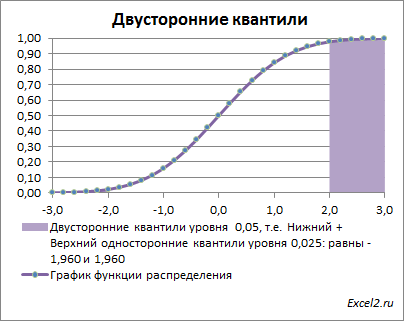
Выражение |Z 0 |>Z α/2 означает, что значение Z 0 попало в одну из выделенных областей. Вероятность события, что случайная величина z попадет в одну из этих областей равна альфа: Р(z>=Z α/2 или z<-Z α/2 ). Это следует из определений квантилей .
Сравним эту вероятность с вероятностью события, что случайная величина z примет значения z>=Z
0
(если Z
0
положительное) или z
Если Z 0 больше 0, то будем вычислять вероятность события, что случайная величина z>=Z 0 . В этом случае вероятность равна 1-Ф(Z 0 ).
Примечание : Ф(z) – интегральная функция стандартного нормального распределения . В MS EXCEL эта функция вычисляется по формуле =НОРМ.СТ.РАСП(Z 0 ;ИСТИНА)
Если Z
0
меньше 0, то будем вычислять вероятность события z
Чтобы учесть оба случая сразу, используем модуль числа |Z 0 |. Для положительного Z 0 наша вероятность равна 1-Ф(|Z 0 |). Для отрицательного Z 0 наша вероятность равна Ф(-|Z 0 |). Используя четность функции плотности стандартного нормального распределения Ф(-|Z 0 |) можно записать как 1-Ф(|Z 0 |).
Следовательно, суммарная вероятность равна 2*(1-Ф(|Z 0 |)). Эта величина Ф(Z 0 ) называется p -значением ( для двусторонней гипотезы ) .
Если p-значение меньше чем заданный уровень значимости α , то нулевая гипотеза отвергается и принимается альтернативная гипотеза . И наоборот, если p-значение больше α, то нулевая гипотеза не отвергается.
Другими словами, если p-значение меньше уровня значимости α, то это свидетельство того, что значение z -статистики , вычисленное на основе выборки, приняло маловероятное значение Z 0 (маловероятное – это при условии истинности нулевой гипотезы ).
В MS EXCEL p -значение для двухсторонней гипотезы вычисляется по формуле (вычисления приведены файле примера на листе Сигма известна ): =2*(1-НОРМ.СТ.РАСП(ABS(Z 0 );ИСТИНА)) Т.е. p-значение равно суммарной вероятности, что z -статистика примет значение больше |Z 0 | и меньше -|Z 0 |.
Для односторонней гипотезы μ 1 - μ 2 > Δ 0 p -значение вычисляется как 1-Ф(Z 0 ). В MS EXCEL p -значение в этом случае вычисляется по формуле =1-НОРМ.СТ.РАСП(Z 0 ;ИСТИНА) Т.е. p-значение равно вероятности, что z -статистика примет значение больше Z 0 .
Для односторонней гипотезы μ 1 - μ 2 < Δ 0 p -значение вычисляется как Ф(Z 0 ). В MS EXCEL p -значение в этом случае вычисляется по формуле =НОРМ.СТ.РАСП(Z 0 ;ИСТИНА) Т.е. p-значение равно вероятности, что z -статистика примет значение меньше Z 0 .
Примечание : В MS EXCEL есть функция Z.TEСT() , которая используется только для одновыборочного z-теста . Подробнее см. статью Проверка статистических гипотез в MS EXCEL о равенстве среднего значения распределения (дисперсия известна) .
Пакет анализа
В надстройке Пакет анализа для проведения двухвыборочного z-теста имеется специальный инструмент: Двухвыборочный z-тест для средних (z-Test: Two Sample for Means).
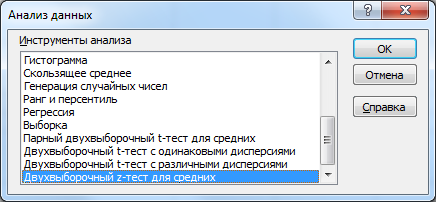
После выбора инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Пакет анализа ):

- интервал переменной 1 : ссылка на значения первой выборки . Ссылку указывать лучше с заголовком. В этом случае, при выводе результата надстройка выводит заголовки, которые делают результат нагляднее (в окне требуется установить галочку Метки );
- интервал переменной 2 : ссылка на значения второй выборки ;
- гипотетическая средняя разность : укажите значение Δ 0 , т.е. μ 1 - μ 2 . В нашем случае, введем 0;
- Дисперсия переменной 1 (известная) : значение дисперсии распределения, из которого взята первая выборка. В нашем случае, введем 100;
- Дисперсия переменной 2 (известная) : значение дисперсии распределения, из которого взята вторая выборка. В нашем случае, введем 144;
- Метки: если в полях интервал переменной 1 и интервал переменной 2 указаны ссылки вместе с заголовками столбцов, то эту галочку нужно установить. В противном случае надстройка не позволит провести вычисления и пожалуется, что « входной интервал содержит нечисловые данные »;
- Альфа: уровень значимости ;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
В результате вычислений будет заполнен указанный Выходной интервал.
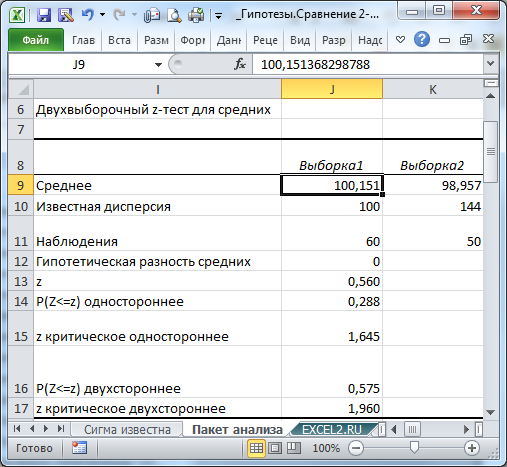
Тот же результат можно получить с помощью формул (см. файл примера лист Пакет анализа ):
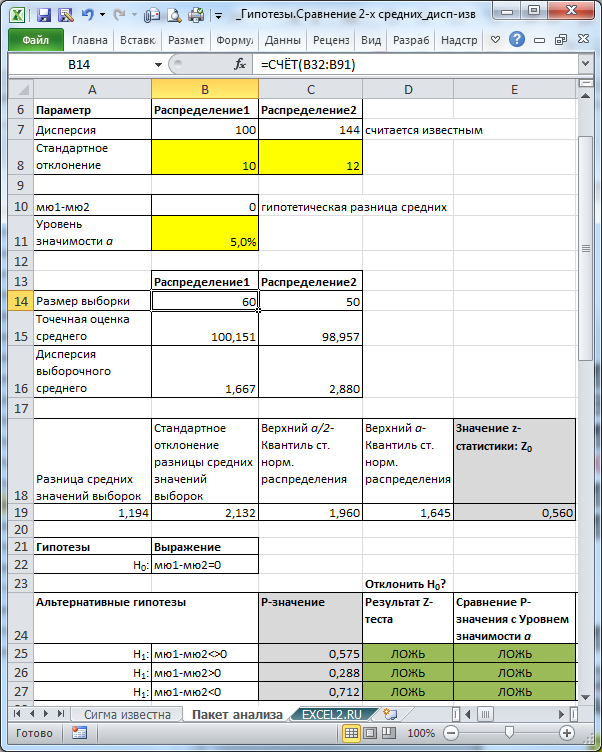
Разберем результаты вычислений, выполненных надстройкой:
- Среднее : средние значения обеих выборок Хср 1 и Хср 2 . Вычисления можно сделать с помощью формул =СРЗНАЧ(B32:B91) и =СРЗНАЧ(C32:C81) ;
- Наблюдения : размер выборок. Вычисления можно сделать с помощью формул =СЧЁТ(B32:B91) и =СЧЁТ(C32:C81)
- z : значение тестовой статистики Z (в наших обозначениях – это Z 0 ). Вычисления можно сделать с помощью формулы =(СРЗНАЧ(B32:B91)- СРЗНАЧ(C32:C81))-0)/ КОРЕНЬ(100/СЧЁТ(B32:B91) +144/СЧЁТ(C32:C81))
- P(Z<=z) одностороннее : р-значение в случае односторонней альтернативной гипотезы μ 1 - μ 2 >Δ 0 . Эквивалентная формула =1-НОРМ.СТ.РАСП(Z 0 ;ИСТИНА) ;
- z критическое одностороннее : Верхний α-Квантиль стандартного нормального распределения . Эквивалентная формула =НОРМ.СТ.ОБР(1- α) ;
- P(Z<=z) двухстороннее: р-значение в случае двухсторонней альтернативной гипотезы μ 1 - μ 2 <>Δ 0 . Эквивалентная формула =2*(1-НОРМ.СТ.РАСП(ABS(Z 0 );ИСТИНА)) ;
- z критическое двухстороннее: Верхний α/2-Квантиль стандартного нормального распределения . Эквивалентная формула =НОРМ.СТ.ОБР(1- α/2) .
СОВЕТ : О проверке других видов гипотез см. статью Проверка статистических гипотез в MS EXCEL .
Комментарии