Подробный разбор задачи (примера) множественной регрессии в EXCEL
26 января 2019 г.
- Группы статей
- Статистический анализ
Рассмотрим пример построения модели множественной регрессии в случае 2-х регрессоров в MS EXCEL.
Подробно модель множественной регрессии рассмотрена в соответствующей статье, которую рекомендуется прочитать перед разбором примера.
Условия задачи
Задача взята из англоязычного учебника «Introduction to Linear Regression Analysis», пятое издание, авторы D.C.Montgomery, E.A. Peck, G.G. Vining
Компания, осуществляющая услуги по обслуживанию торговых автоматов по продаже безалкогольных напитков, анализирует свою деятельность. Компания заинтересована в прогнозировании времени обслуживания одного автомата. Услуга включает доставку напитков до автомата, их размещение в автомат и уборку. Инженер, отвечающий за анализ, предположил, что две наиболее важные переменные, влияющие на время доставки ( Y ) являются: количество напитков, помещаемых в автомат (X1) и расстояние, которое водитель проезжает от склада до автомата (X2). Инженер собрал 25 наблюдений, которые приведены в таблице в файле примера на листе Модель . Для прогнозирования времени доставки необходимо построить модель множественной линейной регрессии.
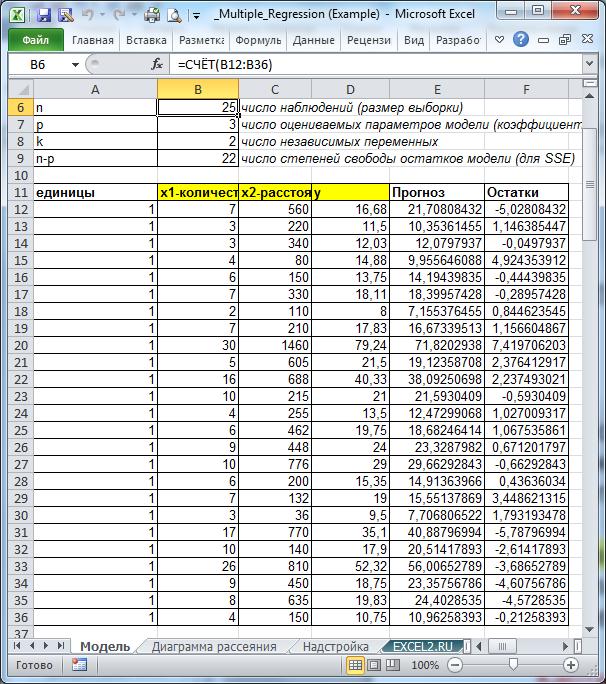
Оценка неизвестных параметров модели
Построение модели выполняется исключительно на основании значений наблюдений, приведенных в таблице B12: D 36 .
Коэффициенты множественной регрессии удобнее всего вычислить в MS EXCEL с помощью функции ЛИНЕЙН() , см. статью Функция MS EXCEL ЛИНЕЙН() . Для этого достаточно ввести формулу ЛИНЕЙН(D12:D36;B12:C36) . Ее нужно ввести как формулу массива (выделить 3 ячейки в строке и нажать CTRL + SHIFT + ENTER ).
Примечание : Коэффициенты регрессии вычисляются на основе метода МНК .
Расчет можно произвести также с помощью матричного подхода - одной формулой массива:
= МУМНОЖ( МОБР(МУМНОЖ(ТРАНСП(A12:C36);A12:C36)); МУМНОЖ(ТРАНСП(A12:C36);D12:D36) )
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b=(X T X) -1 (X T Y) или в другом обозначении транспонированных матриц : b=(X ’ X) -1 (X ’ Y)
Диаграмма рассеяния
Матричная диаграмма рассеивания построена на листе Диаграмма рассеяния в файле примера .
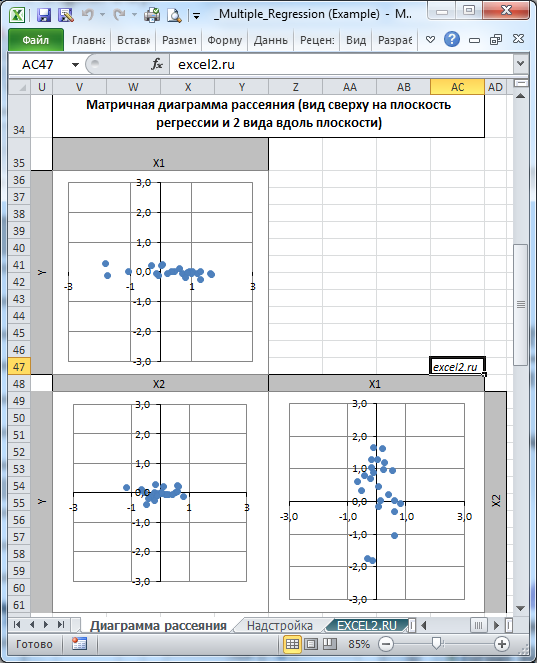
Диаграмма рассеивания представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости. В этом случае удобно наблюдать разброс значений прогнозируемой переменной относительно плоскости регрессии.
Вычисление прогнозных значений Y
В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно предсказать с помощью функции ТЕНДЕНЦИЯ() :
= ТЕНДЕНЦИЯ(D12:D36;B12:C36;L13:M13)
или путем вычисления через уравнение регрессии:
Y= b 0 + b 1 * Х 1 + b 2 * Х 2
Тест на значимость Регрессии
Проверку значимости регрессии можно осуществить через вычисление p-значения. В этом случае вычисляют вероятность того, что тестовая статистика F примет значение F 0 (эта вероятность и есть p -значение ), затем сравнивают p -значение с заданным уровнем значимости . Если p -значение меньше уровня значимости , то имеются основания для отклонения нулевой гипотезы, и регрессия значима.

Значение F 0 вычисляется на основании значений выборки или через функцию ЛИНЕЙН() :
= ИНДЕКС(ЛИНЕЙН(D12:D36;B12:C36;;ИСТИНА);4;1)
p -значение вычисляется по формуле
= F.РАСП.ПХ(F 0 ;k;n-p)
где, n – количество наблюдений (25), p – число оцениваемых параметров модели b (3), k- количество переменных Х (2).
Коэффициент детерминации R 2
Коэффициент детерминации R 2 можно определить по формуле:
= ИНДЕКС(ЛИНЕЙН(D12:D36;B12:C36;;ИСТИНА);3;1)
В регрессионном анализе также часто используют нормированный коэффициент детерминации (Adjusted R-squared):
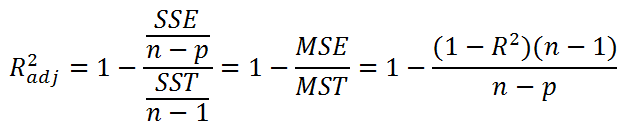
Тест на значимость коэффициентов регрессии
Нулевая гипотеза состоит в том, что коэффициент регрессии bj равен 0. В этом случае тестовая статистика
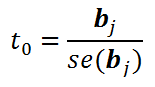
имеет распределение Стьюдента с n-k-1 степенью свободы. При этом стандартная ошибка ( se – standard error ) коэффициента регрессии вычисляется по формуле:
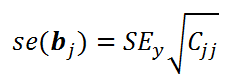
C jj – соответствующий диагональный элемент матрицы (Х’X) -1 .
SEy – стандартная ошибка регрессии .
В MS EXCEL для вычисления стандартной ошибки коэффициента регрессии используется функция ЛИНЕЙН() . Например, для коэффициента b 0 формула будет иметь вид:
= ИНДЕКС(ЛИНЕЙН(D12:D36;B12:C36;ИСТИНА;ИСТИНА);2;3)
В файле примера стандартная ошибка коэффициента регрессии вычислена также впрямую - с использованием матричного подхода. В этом случае нам понадобится вычислить стандартную ошибку регрессии SEy . Ее также можно вычислить через функцию ЛИНЕЙН() :
= ИНДЕКС(ЛИНЕЙН(D12:D36;B12:C36;ИСТИНА;ИСТИНА);3;2)
Либо рассчитать через оценку дисперсии остатков модели (σ 2 ) по формуле:
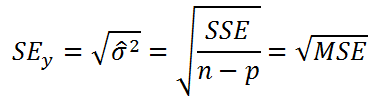
Итак, вычислив значение тестовой статистики, его нужно сравнить с критическим значением, вычисленным для заданного уровня значимости альфа :
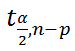 –
квантиль распределения Стьюдента
. В MS EXCEL вычисления квантиля производят по формуле =
СТЬЮДЕНТ.ОБР.2Х(0,05;n-p)
, подробнее см. в статье про
распределение Стьюдента
.
–
квантиль распределения Стьюдента
. В MS EXCEL вычисления квантиля производят по формуле =
СТЬЮДЕНТ.ОБР.2Х(0,05;n-p)
, подробнее см. в статье про
распределение Стьюдента
.
Мы имеем основание отклонить гипотезу Н 0 , если
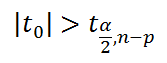
Проверку гипотезы можно осуществить также через р-значение (вероятность того, что тестовая статистика примет значение |t 0 |):
= СТЬЮДЕНТ.РАСП.2Х(ABS(t0);n-p)
Если через р-значение меньше уровня значимости , то гипотеза Н 0 отклоняется.
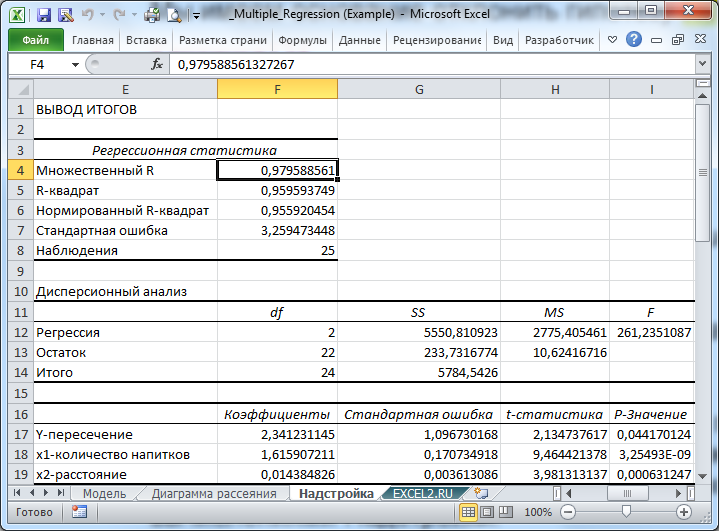
В файле примера на листе Надстройка приведены вычисления с помощью Надстройки Регрессия . Как и ожидалось, все показатели регрессии, вычисленные нами по формулам, совпадают с вычислениями Надстройки .
Комментарии