Подсчет ТЕКСТовых значений, которые имеют повторы в EXCEL
23 апреля 2013 г.
Произведем подсчет ТЕКСТовых значений, которые имеют повторы.
В отличие от статьи Подсчет повторяющихся значений (дубликатов) , где подсчитывались все дубликаты, подсчитаем только первые дубликаты (или другими словами: все повторяющиеся за исключением их повторов, или другой вариант: все уникальные за исключением неповторяющихся). Чтобы не запутаться в этом зоопарке терминов, можно обратиться к статье Классификация значений по уникальности .
Если исходный список содержит: { "a" , "a", "a", "b" , "b", "c"}. Тогда количество значений (величин), которые имеют повторы, будет равно 2, т.е. "a" и "b" (все значения в исходном списке, выделенные жирным ).
Если исходный список значений находится в диапазоне А7:А16 , то количество повторяющихся значений можно вычислить с помощью формулы (см. файл примера ):
=СУММПРОИЗВ((A7:A16<>"")/СЧЁТЕСЛИ(A7:A16;A7:A16&""))- СУММПРОИЗВ(--(СЧЁТЕСЛИ(A7:A16;A7:A16)=1))
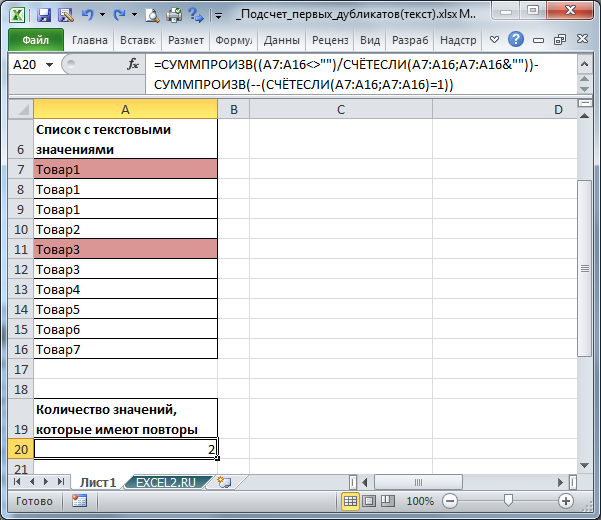
Т.е. для подсчета текстовых значений, которые имеют повторы, необходимо из количества уникальных значений (статья Подсчет уникальных текстовых значений ) вычесть количество неповторяющихся (статья Подсчет неповторяющихся значений ).
Формула подсчитывает текстовые и числовые значения. Диапазон может содержать пустые ячейки.
Первые дубликаты выделены Условным форматированием (см. статью Выделение первых вхождений дубликатов в MS EXCEL ).
Комментарии