Использование Пакета анализа EXCEL для построения простой линейной регрессионной модели
26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем простой регрессионный анализ с помощью надстройки MS EXCEL Пакет анализа .
Эффективно использовать надстройку Пакет анализа для целей регрессионного анализа могут только пользователи знакомые с теорией регрессионного анализа .
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить регрессионный анализ с помощью надстройки Пакет анализа (инструмент Регрессия), т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой.
В надстройке Пакет анализа для построения линейной регрессионной модели (как простой , так и множественной ) имеется специальный инструмент Регрессия .
После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
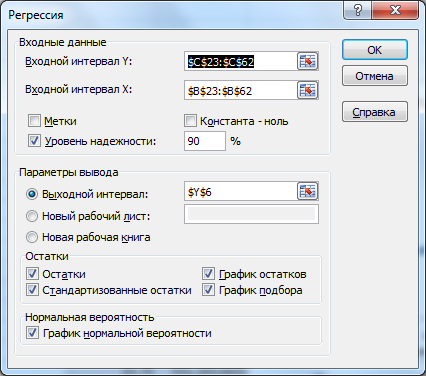
- Входной интервал Y : ссылка на массив значений переменной Y. Ссылку можно указать с заголовком. В этом случае, при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки );
- Входной интервал Х : ссылка на значения переменной Х. В случае множественной регрессии (несколько переменных Х) нужно указать все столбцы со значениями Х. В случае множественной регрессии ссылку рекомендуется делать на диапазон с заголовками (в окне требуется установить галочку Метки );
- Константа-ноль : если галочка установлена, то надстройка подбирает линию регрессии, проходящую через точку Y=0 ( сдвиг будет равен 0);
- Уровень надежности : Это значение используется для построения доверительных интервалов для наклона и сдвига . Уровень надежности = 1- альфа. Если галочка не установлена или установлена, но уровень значимости = 95%, то надстройка все равно рассчитывает границы доверительных интервалов, причем дублирует их. Если галочка установлена, а уровень надежности отличен от 95%, то рассчитываются 2 доверительных интервала : один для 95%, другой для введенного значения. Для демонстрации вышесказанного введем 90%;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона;
- Остатки : будут вычислены остатки модели , т.е. разница между наблюденными и предсказанными значениями Yi для всех наблюдений n;
- Стандартизированные остатки : Вышеуказанные значения остатков будут поделены на значение их стандартного отклонения ;
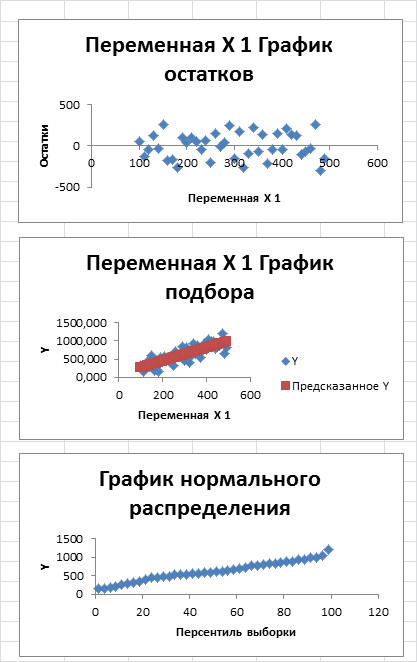
- График остатков : Будет построена точечная диаграмма : значения остатков для всех значений Хi;
- График подбора: Будет построена точечная диаграмма: точки данных (X;Y) и линия регрессии ;
- График нормальной вероятности: Будет построена точечная диаграмма с названием График нормального распределения . По сути - это график значений переменной Y, отсортированных по возрастанию .
В результате вычислений будет заполнен указанный Выходной интервал.

Тот же результат можно получить с помощью формул (см. файл примера лист Надстройка, столбцы I:T ):
Результаты вычислений, выполненных надстройкой, полностью совпадают с вычислениями сделанными нами в статье про простую линейную регрессию с помощью функций ЛИНЕЙН() , НАКЛОН() , ОТРЕЗОК() и др. Использование альтернативных формул помогает разобраться с алгоритмом расчета показателей регрессии.
Отчет, сформированный надстройкой, состоит из следующих разделов:
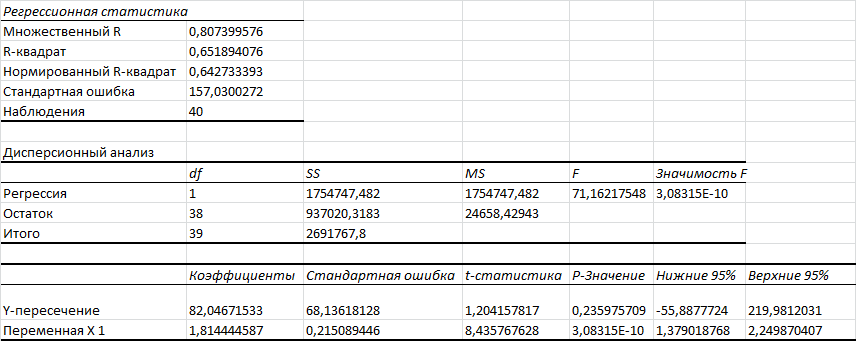
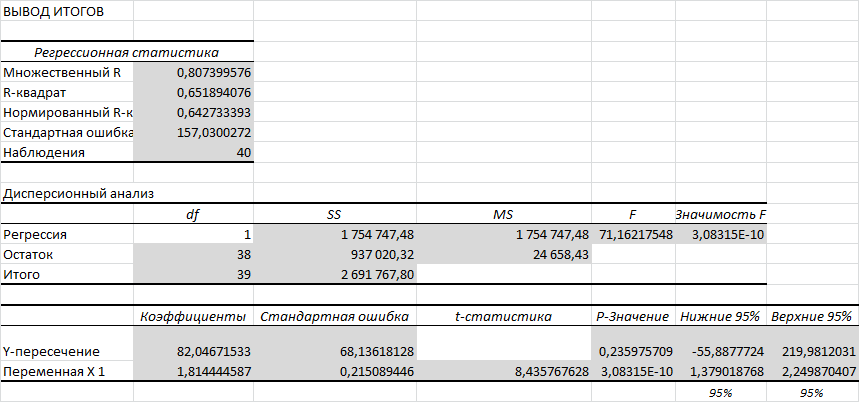
Раздел «Регрессионная статистика»:
- Множественный R. В случае простой линейной регрессии - это Коэффициент корреляции , функция КОРРЕЛ()
- R-квадрат . В случае простой линейной регрессии – это коэффициент детерминации , функция КВПИРСОН()
- Нормированный R-квадрат . См. про коэффициент детерминации .
- Стандартная ошибка . См. Стандартная ошибка регрессии ;
- Наблюдения . Количество значений Y.
Раздел « Дисперсионный анализ »:
См. статью Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
- df – степени свободы (Degrees of Freedom).
- SS – сумма квадратов (Sum of Squares)
- MS – SS/df (MSR и MSE)
- F – значение статистики F 0 (MSR/MSE)
- Значимость F – p-значение, функция F.РАСП.ПХ()
Другие результаты:
- Коэффициенты : оценка параметров модели а и b. См. Оценка неизвестных параметров .
- Стандартная ошибка : Стандартные ошибки вышеуказанных статистик
- t-статистика : значение тестовой статистики t0. См. Проверка значимости взаимосвязи переменных
- P-Значение : См. Проверка значимости взаимосвязи переменных
- Нижние 95% и Верхние 95%: границы доверительных интервалов для оценок неизвестных параметров модели а и b .
Комментарии