Разбор текстовых строк в EXCEL
18 ноября 2017 г.
- Группы статей
- Изменение Текстовых Строк (значений)
Часто текстовая строка может содержать несколько значений. Например, адрес компании: "г.Москва, ул.Тверская, д.13", т.е. название города, улицы и номер дома. Если необходимо определить все компании в определенном городе, то нужно "разобрать" адрес на несколько составляющих. Аналогичный подход потребуется, если необходимо разнести по столбцам Имя и фамилию, артикул товара или извлечь число или дату из текстовой строки.
Данная статья является сводной, т.е. в ней содержатся ссылки на другие статьи, в которых решены определенные задачи. Начнем с адресов.
Самый простейший случай, если адрес, состоящий из названия города, улицы и т.д., импортирован в ячейку MS EXCEL из другой информационной системы. В этом случае у адреса имеется определенная структура (если элементы адреса хранились в отдельных полях) и скорее всего нет (мало) опечаток. Разгадав структуру можно быстро разнести адрес по столбцам. Например, адрес "г.Москва, ул.Тверская, д.13" очевидно состоит из 3-х блоков: город, улица, дом, разделенных пробелами и запятыми. Кроме того, перед названием стоят сокращения г., ул., д. С такой задачей достаточно легко справится инструмент MS EXCEL Текст по столбцам . Как это сделать написано в статье Текст-по-столбцам (мастер текстов) в MS EXCEL .
Очевидно, что не всегда адрес имеет четкую структуру, например, могут быть пропущены пробелы (запятые все же стоят). В этом случае помогут функции, работающие с текстовыми строками. Вот эти функции:
- Функция ЛЕВСИМВ() в MS EXCEL - выводит нужное количество левых символов строки;
- Функция ПРАВСИМВ() в MS EXCEL - выводит нужное количество правых символов строки;
- Функция ПСТР() в MS EXCEL - выводит часть текста из середины строки.
Используя комбинации этих функций можно в принципе разобрать любую строку, имеющую определенную структуру. Об этом смотри статью Разнесение в MS EXCEL текстовых строк по столбцам .
Еще раз отмечу, что перед использованием функций необходимо понять структуру текстовой строки, которую требуется разобрать. Например, извлечем номер дома из вышеуказанного адреса. Понятно, что потребуется использовать функцию ПРАВСИМВ(), но сколько символов извлечь? Два? А если в других адресах номер дома состоит из 1 или 3 цифр? В этом случае можно попытаться найти подстроку "д.", после которой идет номер дома. Это можно сделать с помощью функции ПОИСК() (см. статью Нахождение в MS EXCEL позиции n-го вхождения символа в слове ). Далее нужно вычислить количество цифр номера дома. Это сделано в файле примера , ссылка на который внизу статьи.
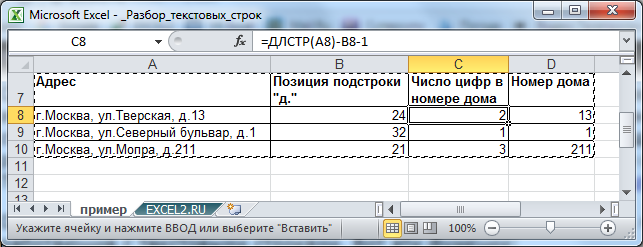
Усложним ситуацию. Пусть подстрока "д." может встречаться в адресе несколько раз, например, при указании названия деревни используется сокращение "д.", т.е. совпадает с префиксом номера дома. В этом случае нужно определить все строки, в которых имеется название деревень (первые 2 символа, т.к. это адрес населенного пункта) и исключить их. Также можно извлечь все цифры из строки в отдельный диапазон (см. статью Извлекаем в MS EXCEL число из конца текстовой строки ). Но, что делать, если в названии улицы есть числа? Например, "26 Бакинских комиссаров". Короче, тут начинается творчество.
Не забудьте про пробелы! Каждый пробел - это отдельный символ. Часто при печати их ставят 2 или 3 подряд, а это совсем не то же самое, что один пробел. Используйте функцию Функция СЖПРОБЕЛЫ() в MS EXCEL , чтобы избавиться от лишних пробелов.
Об извлечении чисел из текстовой строки см. здесь: Извлекаем в MS EXCEL число из начала текстовой строки или здесь Извлекаем в MS EXCEL число из середины текстовой строки .
Об извлечении названия файла из полного пути см. Извлечение имени файла в MS EXCEL .
Про разбор фамилии см. Разделяем пробелами Фамилию, Имя и Отчество .
Часто в русских текстовых строках попадаются английские буквы . Их также можно обнаружить и извлечь, см. Есть ли в слове в MS EXCEL латинские буквы, цифры, ПРОПИСНЫЕ символы .
Все статьи сайта, связанные с преобразованием текстовых строк собраны в этом разделе: Изменение Текстовых Строк (значений) .
Артикул товара
Пусть имеется перечень артикулов товара: 2-3657; 3-4897; ...
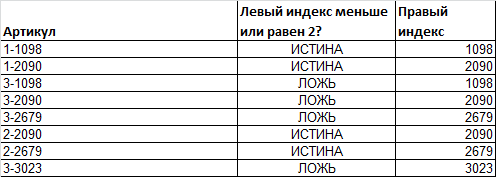
Как видно, артикул состоит из 2-х числовых частей, разделенных дефисом. Причем, числовые части имеют строго заданный размер: первое число состоит из 1 цифры, второе - из 4-х.
Задача состоит в том, чтобы определить артикулы, у которых левый индекс <=2 и вывести для них правый индекс.
Первая часть задачи решается формулой =--ЛЕВСИМВ(A16;1)<=2 или =ЗНАЧЕН(ЛЕВСИМВ(A16;НАЙТИ("-";A16;1)-1))<=2 . Вторая формула понадобится, если длина первого индекса не обязательна равна 1 (см. файл примера ).
Вторая часть задачи решается формулой =ЗНАЧЕН(ПРАВСИМВ(A16;4)) .
Зачем нам потребовалась функция ЗНАЧЕН() ? Дело в том, что текстовые функции, такие ка ПРАВСИМВ() , возвращают текст, а не число (т.е. в нашем случае число в текстовом формате). Для того, чтобы применить к таким числам в текстовом формате операцию сравнения с другим числом, т.е. <=2, потребуется сначала преобразовать текстовый формат в числовой формат . Самый простой для этого способ - использовать функцию ЗНАЧЕН() или попытаться применить к нему арифметическую операцию, например, двойное вычитание -- или *1 или +0.
ВНИМАНИЕ!
Если у Вас есть примеры или вопросы, связанные с разбором текстовых строк - смело пишите в комментариях к этой статье или в группу ]]> https://vk.com/excel2ru ]]> ! Я дополню эту статью самыми интересными из них.
Комментарии