Разнесение в EXCEL текстовых строк по столбцам
4 апреля 2013 г.
- Группы статей
- Изменение Текстовых Строк (значений)
Разнесем Фамилию, Имя и Отчество (ФИО), содержащихся в одной ячейке, по разным столбцам.
Инструмент Текст-по-столбцам (вкладка Данные , группа Работа с данными , пункт Текст-по-столбцам ) используется для разнесения элементов текстовой строки по различным столбцам.
Однако, если исходные текстовые строки имеют разный формат, например, если в некоторых ФИО отсутствует отчество, то у инструмента Текст-по-столбцам могут сложности с корректным отнесением значений в столбцы. Можно наблюдать такую картину:
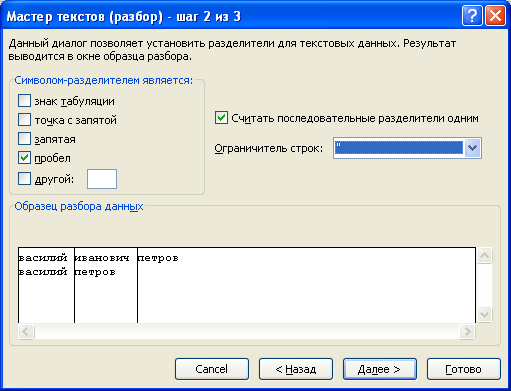
Т.е. фамилия будет помещена в столбец с отчествами.
Рассмотрим вариант разделения ФИО по столбцам с помощью формул. Перед использованием формул исходную строку нужно пропустить через функцию СЖПРОБЕЛЫ() .
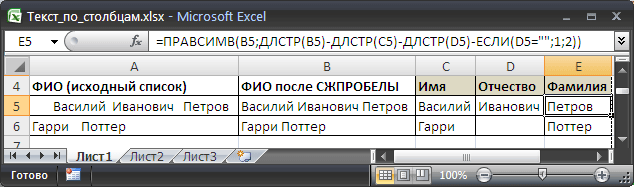
Определяем Имя (см. файл примера ) =ЛЕВСИМВ(B5;ПОИСК(" ";B5;1)-1)
Формула ищет первый пробел и все, что левее его относит к имени.
Определяем Отчество: =ЕСЛИ(ЕОШИБКА(ПОИСК(" "; ПРАВСИМВ(B5; ДЛСТР(B5) - ПОИСК(" "; B5; 1)); 1)) = ИСТИНА; ""; ЛЕВСИМВ(ПРАВСИМВ(B5;ДЛСТР(B5) - ПОИСК(" "; B5; 1)); ПОИСК(" "; ПРАВСИМВ(B5; ДЛСТР(B5) - ПОИСК(" "; B5; 1)); 1) - 1))
Формула определяет, есть ли Отчество, и если находит, то отображает его. Фактически она определяет наличие второго пробела.
Определяем Фамилию: =ПРАВСИМВ(B5;ДЛСТР(B5)-ДЛСТР(C5)-ДЛСТР(D5)-ЕСЛИ(D5="";1;2))
Формула основывается на результатах вычисления двух предыдущих формул и выводит всю исходную строку за исключением Имени и Отчества.
Этот подход не является универсальным для разделения строк по столбцам. Он работает, если строка содержит только 3 или 2 составляющих. В случае со строкой из 4-х слов (например, Василий Петрович Лукьяненко мл. ) будет получен неудовлетворительный результат.
Реальный пример
В реальной жизни все гораздо сложнее, взгляните на следующий исходный список с адресами (в файле примера есть список с 46 адресами).

Предположим, что нужно выделить из каждой строки название улицы или проезда, но только в городе Саратов (исходный список может содержать и другие города).
Проанализируем исходный список.
1) очевидно, что данные взяты из некой электронной базы данных, т.к. в строках имеются характерные запятые, которыми отделяют названия города, улиц, номера домов и пр. (Когда данные заводятся в определенные поля их потом "сшивают" в одну строку, отделяя запятыми или иногда другими знаками, например, пробелами). Имеет смысл запросить исходный файл или попросить выгрузить данные не просто в единую текстовую строку, а в отдельные столбцы. Если это невозможно, то идем дальше.
2) похоже, что данные вводились не совсем корректно. Например, во всех строках, кроме 4-й и 7-й, после символа города "Г" стоит 2 запятые. Вроде мелочь, но если мы будем писать формулу для определения названия города, то подстрока "Г,," будет служить меткой окончания названия города и начала названия улицы. Это очень удобно.
3) название города каждый раз заводилось вручную, а не выбиралось, поэтому есть орфографические ошибки (третья красная строка содержит название города СРАТОВ, что явно ошибочно)
4) далеко не каждая строка содержит обозначение улицы (УЛ) или проезда (ПРОЕЗД). Наличие таких слов существенно облегчает написание формул. Можно было бы определять окончание названия улицы по обозначению номера дома "Д.", но далеко не в каждой строке номер дома идет с этой меткой (2-я, 3-я и 4-я красная строка не содержат метку "Д.").
5) наконец мы имеем множество типов названий улиц: собственно УЛ, затем ПРОЕЗД, потом еще есть РЗД (?), или вообще без обозначения (1-я красная строка).
КАЖДАЯ ошибка, КАЖДЫЙ неверный формат и КАЖДЫЙ тип улицы - обрабатывается написанием ОТДЕЛЬНОЙ формулы. Это трудоемкая и неблагодарная работа, т.к. исходные списки постоянно обновляются привнося новые ошибки.
Как поступить? Я сделал так:
1) в ручную убрал орфографические ошибки. Тут автоматизация пасует. Разнообразие ошибок непредсказуемо
2) использовал только 2 типа названий: Проезд и УЛ,
Все это позволило отобрать из 46 записей, 32. По аналогии можно дописать другие типы улиц: РЗД, тупик, ПР.
 Сначала я определил к какому городу относится каждая запись: =ПОИСК(",,,САРАТОВ Г,,";$A10) Строки, где есть г.Саратов, выводится число 1, что соответствует позиции с которой начинается подстрока ,,,САРАТОВ Г,, Если это другой город, то формула возвращает ошибку.
Сначала я определил к какому городу относится каждая запись: =ПОИСК(",,,САРАТОВ Г,,";$A10) Строки, где есть г.Саратов, выводится число 1, что соответствует позиции с которой начинается подстрока ,,,САРАТОВ Г,, Если это другой город, то формула возвращает ошибку.
Затем, аналогичной формулой выясняем есть ли в адресе метка "УЛ,": =ПОИСК("УЛ,";$A10) или "ПРОЕЗД". В третьей строке есть и УЛ и ПРОЕЗД. Хотя это, очевидно, ошибка, но ее можно обработать. Приоритет отдадим Проезду (см. столбец Позиция).
Следующий столбец Отступ учитывает различие в длине слов ПРОЕЗД и УЛ, чтобы название улицы (или проезда) было корректной длины.
Наконец, окончательная формула =ЕСЛИ(ЕОШ(ПСТР(A10;ДЛСТР($B$7)+1;E10-ДЛСТР($B$7)+F10-1));"";ПСТР(A10;ДЛСТР($B$7)+1;E10-ДЛСТР($B$7)+F10-1)) выводит название улицы:
- игнорируются адреса вне города Саратов,
- отбрасывается название города, ищутся только Улицы и Проезды (игнорируются все остальные типы улиц: тупики, проспекты, бульвары и пр.)
- отбрасывается номер дома и квартиры
В файле примера из полученного списка названий улиц и проездов убираются повторы. Затем список улиц сортируется. Сортировка нужна для определения ошибок, которые мы не нашли в исходном списке.

Видно, что 2 красные строки содержат одно и тоже название проезда, разница только в наличии дефиса.
Вывод: разбор тектовых строк - занятие творческое, универсальной формулы не существует. Единственная панацея от ошибок в исходном списке - запретить ввод данных, а разрешить только выбор из заранее определенных списков.
Комментарии