Отбор уникальных значений с вычислением среднего из соседнего столбца в EXCEL
22 апреля 2013 г.
- Группы статей
- Отбор на основании повторяемости
- Вычисление Среднего
- Уникальные
- Пользовательский формат
- Сложение, МАКС/МИН на основании уникальности
- Условное форматирование
Имеется таблица, состоящая их двух столбцов: из столбца с повторяющимися текстовыми значениями и столбца с числами. Создадим таблицу состоящую только из строк с уникальными текстовыми значениями. По числовому столбцу произведем вычисление среднего.
Разовьем идеи, изложенные в статье Отбор уникальных значений (убираем повторы) .
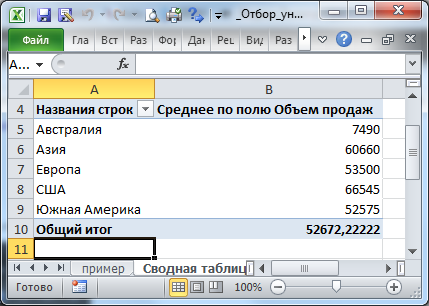
Пусть исходная таблица содержит 2 столбца: текстовый – Список регионов и числовой - Объем продаж . Столбец Список регионов содержит повторяющиеся значения (см. файл примера ). Уникальные значения выделены цветом с помощью Условного форматирования .
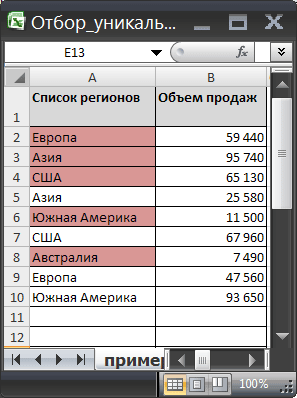
Задача
Создадим на основе исходной, таблицу, в которой в столбце с перечнем регионов будут содержаться только уникальные названия регионов (т.е. без повторов), а в соседнем столбце будут вычислены средние продажи для каждого региона.
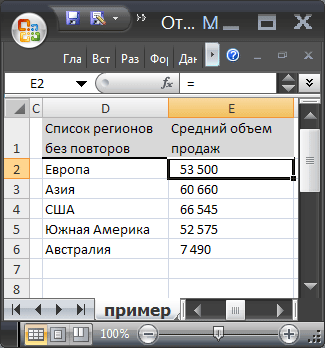
Решение
Создадим Динамические диапазоны : Регионы (названия регионов из столбца А ) и Продажи (объемы продаж из столбца B ).
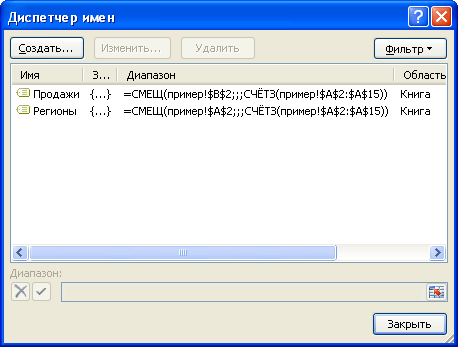
Если в исходный список будет добавлено новое значение, то оно будет автоматически включено в Динамический диапазон и нижеследующие формулы не придется модифицировать.
Для создания списка уникальных значений введем в ячейку D2 формулу массива : =ЕСЛИОШИБКА(ИНДЕКС(Регионы; ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$1:D1;Регионы);0));"")
Для подсчета средних продаж в столбце E запишем формулу: =ЕСЛИОШИБКА(СУММЕСЛИ(Регионы;D2;Продажи)/ СЧЁТЕСЛИ(Регионы;D2);"")
Отображение нулей в строках, в которых нет регионов, уберем пользовательским форматом # ##0;-# ##0; (см. статью Скрытие значений равных 0 ).
Тестируем
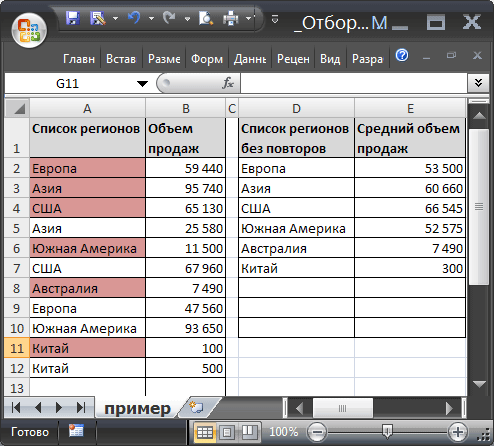
1. Введите в ячейку А11 новый регион - Китай 2. Введите объем продаж - 100 3. Введите в А12 - Китай 4. Введите объем продаж - 500 5. В соседней таблице справа в ячейке D7 будет выведено название региона Китай со средним объемом продаж 300
СОВЕТ: Другим подходом к решению этой задачи является использование Сводных таблиц .
Комментарии