Отбор уникальных СТРОК в EXCEL
22 апреля 2013 г.
- Группы статей
- Отбор на основании повторяемости
- Отбор строк в таблице
- Уникальные
- Расширенный фильтр
- Условное форматирование
Для извлечения из таблицы только уникальных строк (строк без повтора) можно использовать формулы.
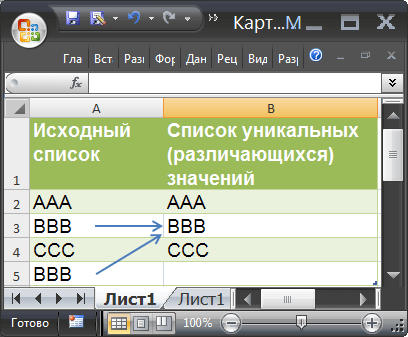
Под «отбором уникальных строк» в статье понимается фильтрация таблицы для исключения всех повторных вхождений строк (одинаковых строк может быть, к примеру 3, но в отфильтрованную таблицу войдет только одна).
Создайте таблицу состоящую из 2-х столбцов (полей): Номер_заказа и КодТовара (см. файл примера ).
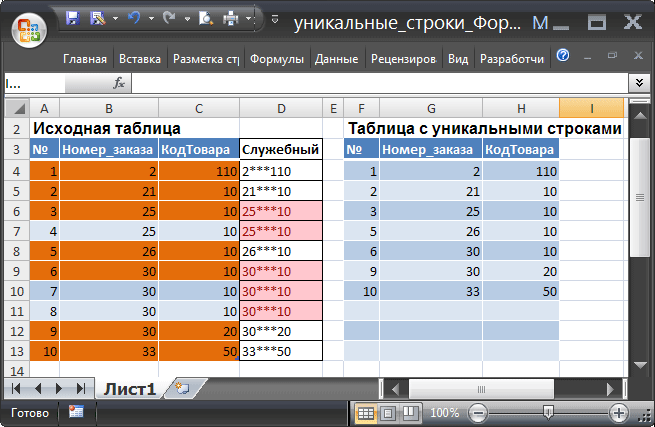
Строки таблицы 3 и 4 , а также 6, 7, 8 считаются одинаковыми строками, т.к. в них значения полей Номер_заказа и КодТовара совпадают. По этим строкам будет производиться группировка. В итоге, будет сформирована новая таблица, содержащая только уникальные строки, например, вместо трех строк 6, 7 и 8 получим одну строку.
Отбор строк по 2-м полям можно свести к задаче отбора строк по одному полю. Для этого сформируем из 2-х столбцов один Служебный (столбец D ) с помощью операции конкатенации ( Номер_заказа&КодТовара ).
В ситуации, когда две строки в полях Номер_заказа и КодТовара содержат соответственно 21; 10 и 2; 110 (см. рис. строки 1 и 2), то есть являются разными строками; объединение столбцов посредством обычной конкатенации ( Номер_заказа&КодТовара ) приводит к тому, что в столбце Служебный для двух строк будет одинаковое значение 2110. А такие строки будут считаться одинаковыми. Поэтому для конкатенации дополнительно используем набор символов *** (предполагаем, что *** заведомо не могут встретиться в этих строках): Номер_заказа&"***"&КодТовара.
Теперь начнем создавать новую таблицу. В столбце Номер_заказа ( G ) введем формулу массива : =ЕСЛИОШИБКА(ИНДЕКС($B$4:$B$13;НАИМЕНЬШИЙ( ЕСЛИ(ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0)<>СТРОКА($D$4:$D$13) -СТРОКА($D$3);"повтор";СТРОКА($D$4:$D$13)-СТРОКА($D$3));СТРОКА(1:1)));"")
Поясним:
- Выделим часть формулы ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0) и нажмем клавишу F9 , получим массив {1:2:3:3:5:6:6:6:9:10} с позициями первых вхождений значений в столбце Служебный ;
Если номер позиции не совпадает с текущей позицией ( ПОИСКПОЗ($D$4:$D$13;$D$4:$D$13;0)<>СТРОКА($D$4:$D$13)-СТРОКА($D$3) ), то значит это значение - повтор , и его не нужно включать в новую таблицу. Результатом функции ЕСЛИ() является массив с номерами позиций уникальных значений и словами « повтор »;
- Функция НАИМЕНЬШИЙ() сортирует массив и поэлементно выводит его;
- Функция ИНДЕКС() выбирает из столбца исходной таблицы ( Номер_заказа ) соответствующее значение.
В столбцах F и H запишем формулу массива подобную вышерассмотренной.
В итоге, получим таблицу (столбцы F , G , H ) без повторов (см. рисунок выше).
СОВЕТ: Список уникальных строк можно создать разными способами, например, с использованием Расширенного фильтра (см. статью Отбор уникальных строк с помощью Расширенного фильтра ) или Сводных таблиц .
Комментарии