Отбор повторяющихся значений (дубликатов) со значениями из соседнего столбца в EXCEL
22 апреля 2013 г.
- Группы статей
- Повторяющиеся
- Отбор на основании повторяемости
- Вывод отобранных значений в отдельный диапазон
- Условное форматирование
Имея список с повторяющимися текстовыми значениями, создадим список, состоящий только из дубликатов . А из соседнего столбца, выведем соответствующие числовые значения.
Пусть исходная таблица содержит 2 столбца: текстовый – Список регионов (в столбце А ) и числовой - Объем продаж (в столбце B ). Столбец Список регионов содержит повторяющиеся значения.
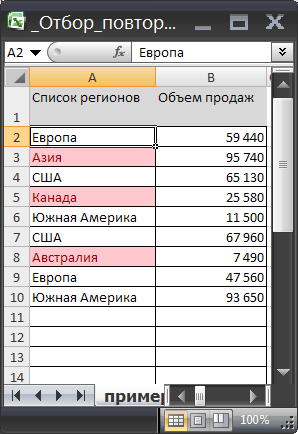
Названия регионов в исходной таблице, которые НЕ имеют повторов и соответственно НЕ должны быть выведены, выделены цветом с помощью Условного форматирования .
Задача
Создадим таблицу, в которой в столбце с перечнем регионов будут содержаться только те значения из исходной таблицы, которые имеют повторы (т.е. те, которые НЕ выделены Условным форматированием в исходной таблице), а рядом выведем соответствующие объемы продаж.
Решение
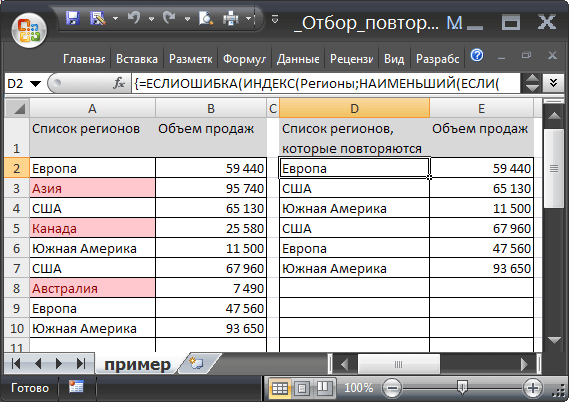
Используем идеи, изложенные в статье Отбор повторяющихся значений . Но, теперь не будем производить группировку дубликатов, а выведем их все вместе с соответствующими значениями из соседнего столбца (см. файл примера ). Для создания списка дубликатов введем в ячейку D2 формулу массива :
=ЕСЛИОШИБКА(ИНДЕКС(Регионы;НАИМЕНЬШИЙ( ЕСЛИ(СЧЁТЕСЛИ(Регионы;Регионы)>1;СТРОКА(Регионы)-МИН(СТРОКА(Регионы))+1;""); СТРОКА(A1)));"")
Динамический диапазон Регионы представляет собой исходный список с названиями регионов, причем его границы изменяются в зависимости от количества числа введенных значений в столбец А (пропуски не допускаются). Для этого использована формула =СМЕЩ(пример!$A$2;;;СЧЁТЗ(пример!$A$2:$A$26)) . Аналогичный диапазон Продажи создан для списка Объем продаж . Теперь при вводе новых значений в столбцы А и В , таблица с дубликатами будет обновляться автоматически.
Соответствующие дубликатам Объемы продаж выведены в столбце E с помощью аналогичной формулы массива .
Однако, столбец дубликатов не сортирован, что затрудняет анализ списка. Для сортировки таблицы по Объему продаж создадим 2 служебных столбца:
- Столбец G содержит формулу =ЕСЛИ(D2<>"";СЧЁТЕСЛИ(Дубликаты;"<"&D2)+1;"") , которая подсчитывает число значений меньше и равных текущему;
- Столбец Н содержит формулу =ЕСЛИ(D2<>"";ЕСЛИ(СЧЁТЕСЛИ($G$2:G2;G2)=1;G2;G2+СЧЁТЕСЛИ($G$2:G2;G2)-1);"") для правильной нумерации дубликатов.
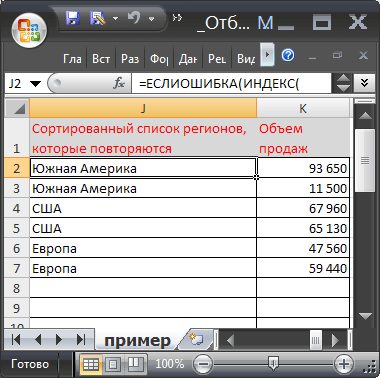
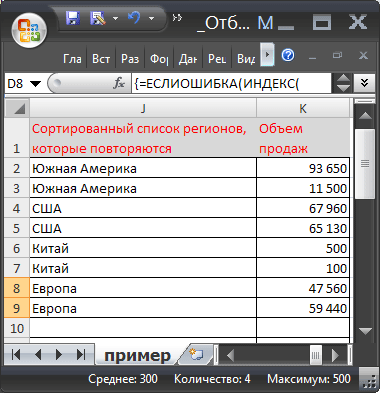
Теперь записав в столбец J формулу массива : =ЕСЛИОШИБКА(ИНДЕКС(Дубликаты;ПОИСКПОЗ(СЧЁТЗ(Дубликаты)-(СТРОКА()-СТРОКА($H$2));ДубликатыСорт;0));"")
Получим отсортированный список дубликатов. Аналогичную формулу запишем в столбце K для вывода соответствующих значений из смежного столбца. В результате получим новую таблицу.
Тестируем
1. Введите в ячейку А11 новый регион - Китай 2. Введите объем продаж - 100 3. Введите в А12 - Китай 4. Введите объем продаж - 500 5. В соседней таблице справа в ячейках D8 и D9 будут автоматически выведены 2 названия региона Китай с соответствующими объемами продаж (т.к. название региона Китай повторяется).
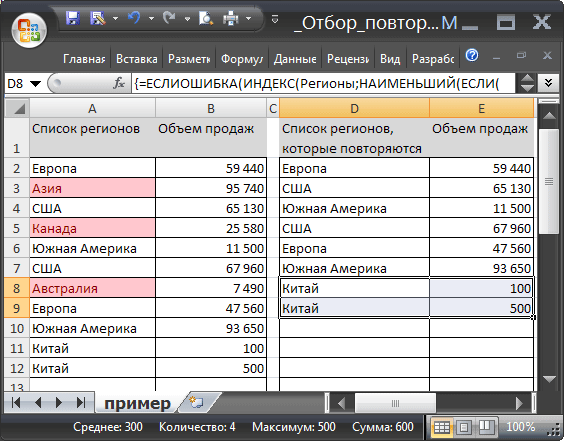
6. В таблице с отсортированным списком повторяющихся регионов будут также выведены 2 названия региона Китай с соответствующими объемами продаж, но уже с учетом сортировки по алфавиту (в обратном порядке).
СОВЕТ: Другим подходом к решению этой задачи является использование Сводных таблиц .
Комментарии