Использование Пакета анализа EXCEL для выполнения двухфакторного дисперсионного анализа (без повторений)
26 января 2019 г.
- Группы статей
- Статистический анализ
Выполним двухфакторный дисперсионный анализ без повторений с помощью надстройки MS EXCEL Пакет анализа .
Эффективно использовать надстройку Пакет анализа (Анализ данных) могут только пользователи знакомые с теорией двухфакторного дисперсионного анализа .
В данной статье решены следующие задачи:
- Показано как в MS EXCEL выполнить двухфакторный дисперсионный анализ без повторений с помощью надстройки Пакет анализа , т.е. как вызвать надстройку и правильно заполнить входные данные;
- Даны пояснения по разделам отчета, формированного надстройкой.
В качестве исходных данных используем тот же массив данных, что и в основной статье про двухфакторный дисперсионный анализ без повторений .
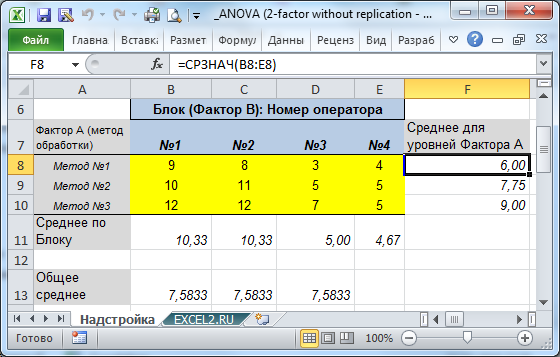
В диапазоне В8:Е10 файла примера построчно введены 4 выборки, представляющие значения зависимой переменной Y ( количество дефектов ), измеренные при 4-х различных уровнях фактора А (метод обработки поверхности ). Одновременно, все значения Y объединены в блоки, соответствующие номеру оператора, который проводит обработку поверхности выбранным методом.
В задаче необходимо исследовать вопрос: является ли связь между методом обработки (первый фактор) и количеством дефектов значимой. Ответ на этот вопрос положительный в том случае, если средние значения соответствующих выборок статистически значимо различаются. Для того, чтобы исключить влияние на качество обработки поверхности самого оператора, также анализируется влияние каждого оператора на переменную Y(второй фактор).
Чтобы ответить на этот вопрос воспользуемся надстройкой Пакет анализа . В этой надстройке имеется инструмент двухфакторный дисперсионный анализ без повторений (Two-Factor Without Replication).

После выбора этого инструмента откроется окно, в котором требуется заполнить следующие поля (см. файл примера лист Надстройка ):
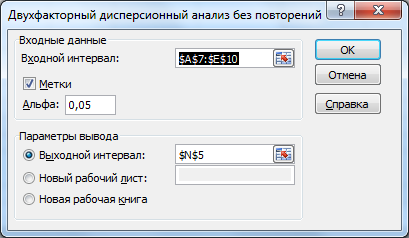
- Входной интервал : ссылка на массив значений выборок. Ссылку лучше указать с заголовками (в нашем случае включены названия строк и столбцов). Теперь при выводе результатов надстройка использует Ваш заголовок (для этого в окне требуется установить галочку Метки );
- Альфа: уровень значимости . Это значение используется для проверки гипотезы о различии средних значений выборок . Чаще всего для уровня значимости используют значения 0,01; 0,05; 0,10;
- Выходной интервал: диапазон ячеек, куда будут помещены результаты вычислений. Достаточно указать левую верхнюю ячейку этого диапазона.
Заполнив все поля диалогового можно нажимать кнопку ОК. Расчет будет выполнен в двух таблицах: ИТОГИ и Дисперсионный анализ.
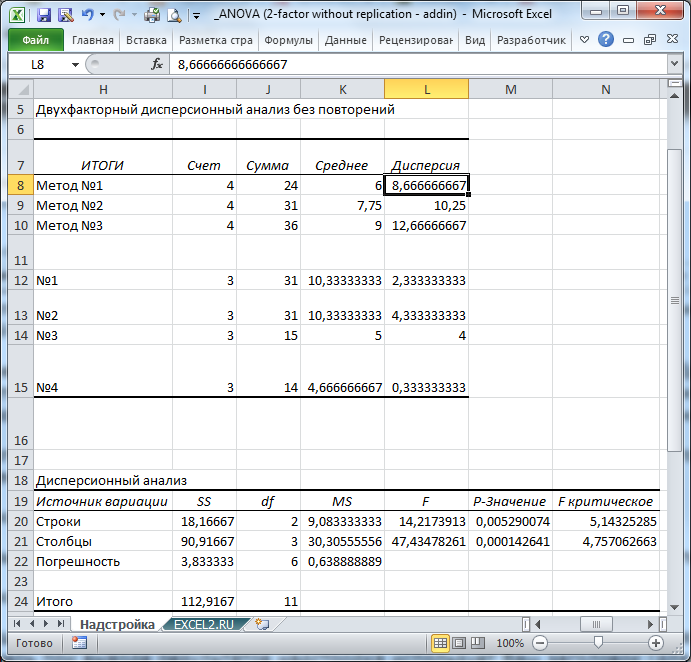
Тот же результат можно получить с помощью формул (см. файл примера, столбцы A:G ).
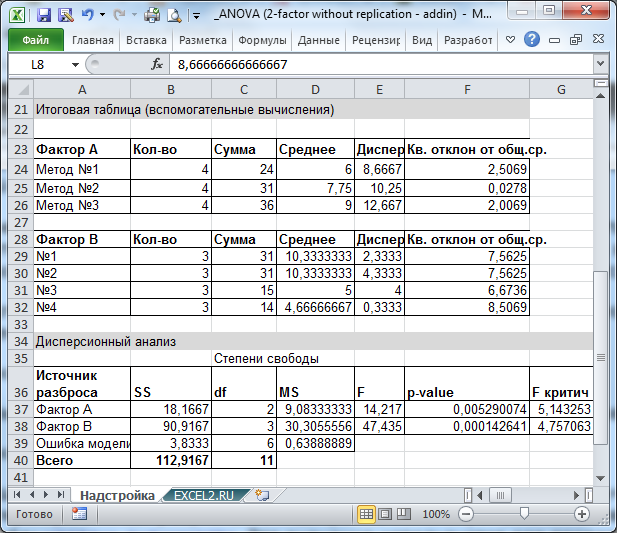
Подробный разбор формул приведен в основной статье про двухфакторный дисперсионный анализ без повторений .
Комментарии